- Solutions


- Use cases
- { Documentation }
- Resources
- Company
- Solutions
- Industries
- Use cases
Platform
Easy data management
at your fingertips
Your visual assistant to generation at scale
Scaling up data generation can present challenges, particularly when it comes to managing tracking, and visualizing the full range of options available to you through an API. The Datagen Platform complements our API by allowing you to easily preview the various assets, generate in a lightweight, iterative way, and retrieve previously generated data.

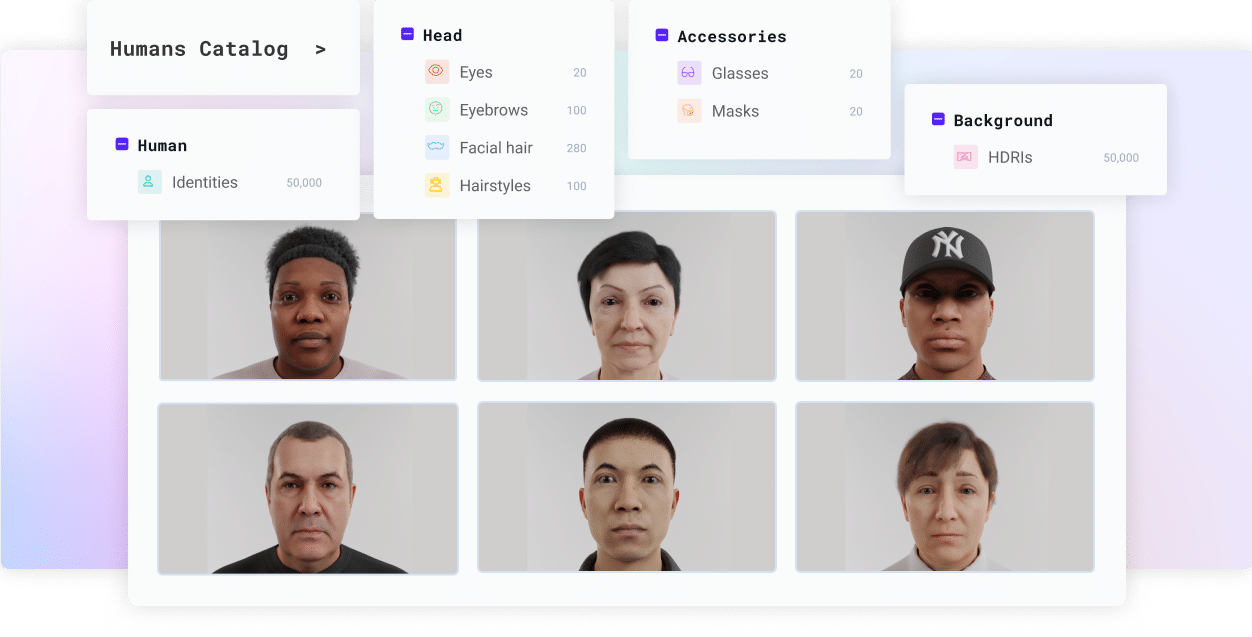
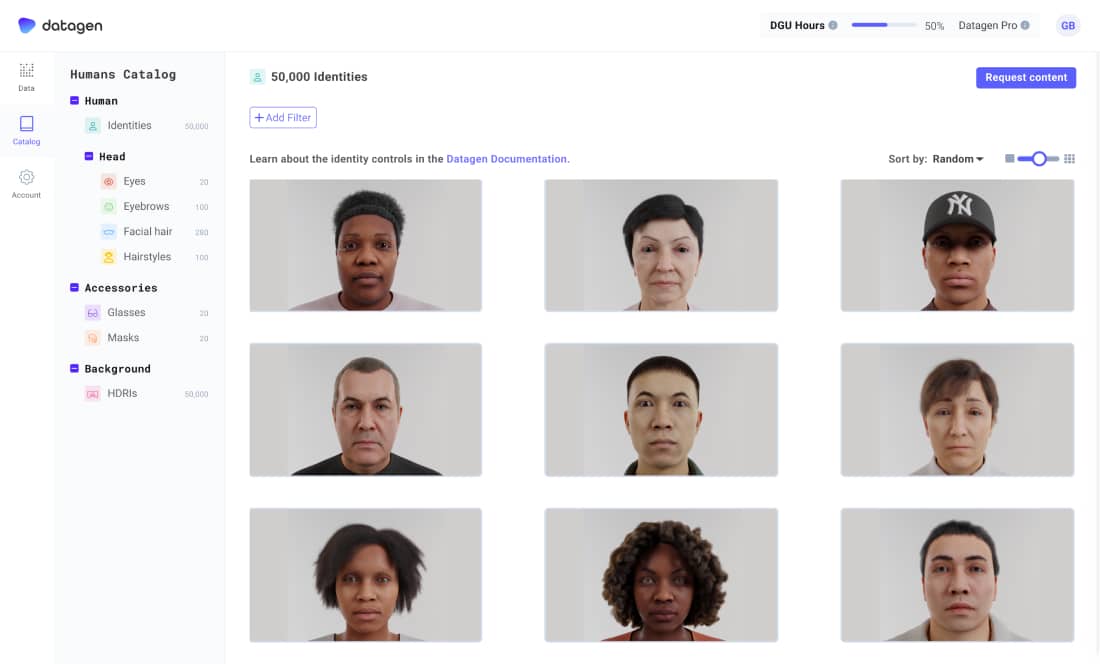
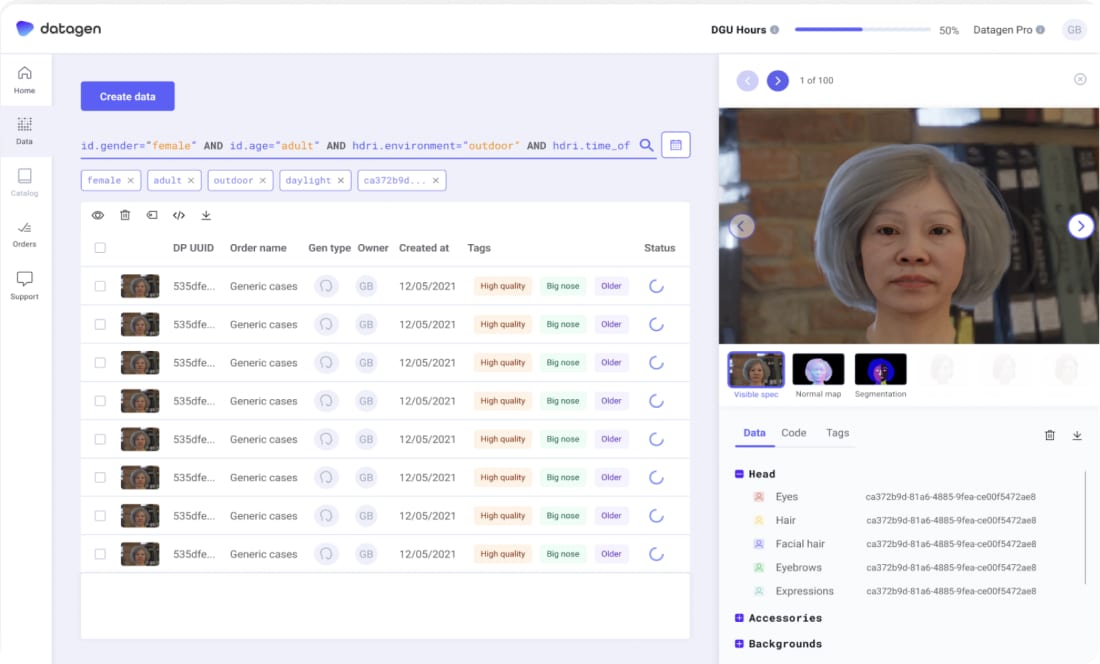
Browse and select
Our platform includes a catalog of all identities and assets. Browse through the options to select the exact data you need and import it into our API.

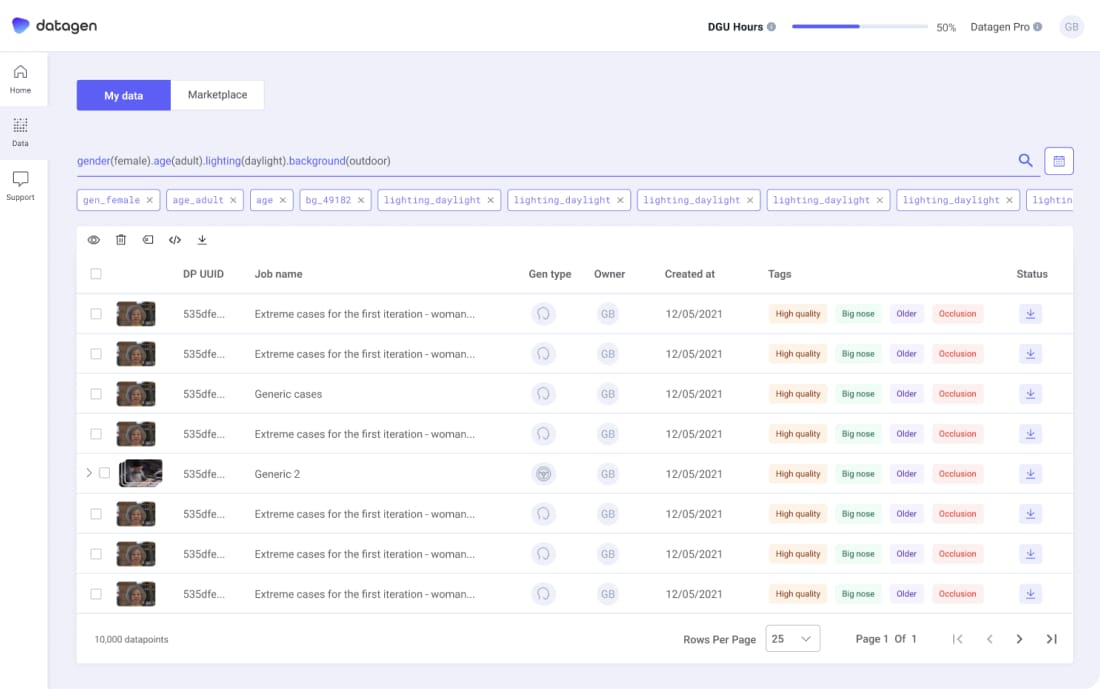
Manage and share
Manage and share synthetic data within your team or company with ease. With the platform’s intuitive interface, you can quickly query to find data points of specific characteristics whether it was generated by you or others on your team.

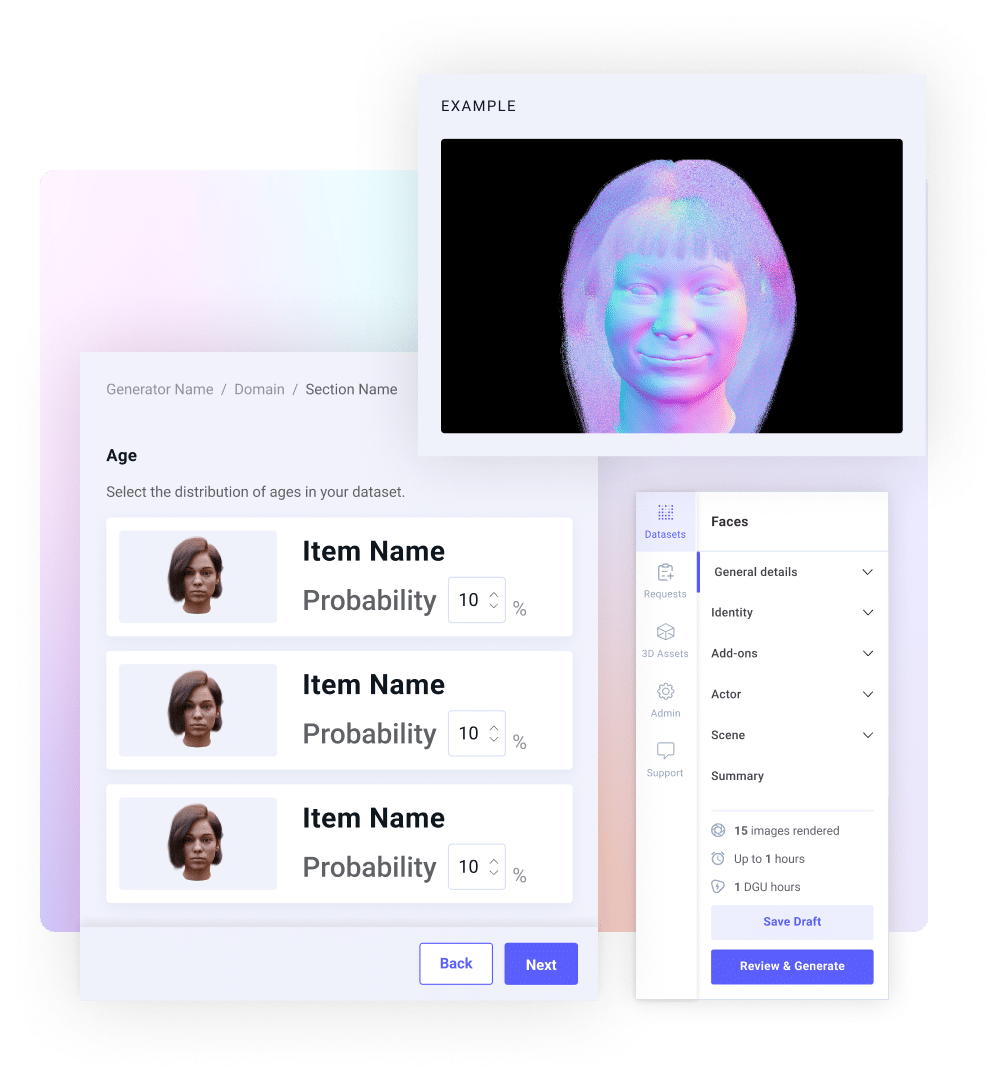
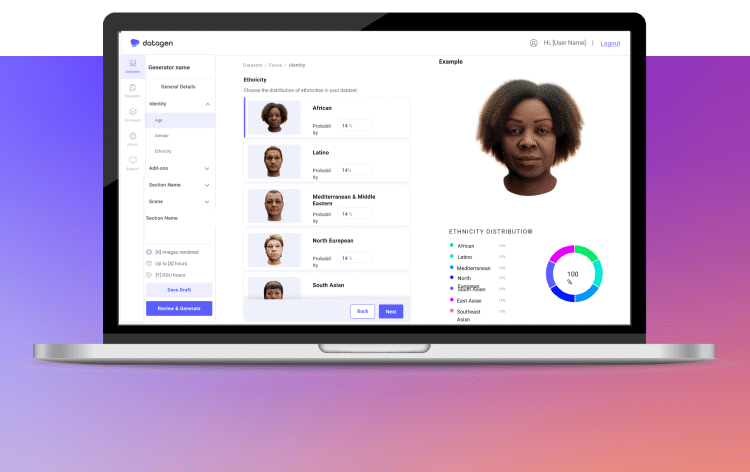
Generate quickly and easily
The platform allows you to quickly generate data before diving into our API and SDK. Choose the humans and/or behaviors that you want to generate and get your data with the click of a button.
To generate data on a large scale with granular control over every parameter, the API is the solution for you.
I think the quality of the data, sophistication,
and the platform looks really good. So kudos on that. That’s amazing.
Generate data with API
Manage and share synthetic data within your team or company with ease. With the platform’s intuitive interface, you can quickly query to find data points of specific characteristics whether it was generated by you or others on your team.
Our data
100k+ Unique Identities, perfect ground truth, high domain variance, everything you need to train, test and cover data gaps in your computer vision model.
Try the Datagen Platform
Data management, generation
and sharing
- Use cases
- Industries
- Solutions
- Company



- Resources
- { Documentation }